”spark streaming“ 的搜索结果
spark streaming streaming
java的sparkstreaming连接kafka的例子,kafka生产者生产消息,消费者读取消息,sparkstreaming读取kafka小区并进行存储iotdb数据库。
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着时代发展,hadoop只适用于离线数据的...SparkStreaming是微批处理,每隔一段时间处理一次,每隔一段时间将接收到的数据封装成一个rdd, 再触发一个job处理r.
一个完善的Spark Streaming二次封装开源框架,包含:实时流任务调度、kafka偏移量管理,web后台管理,web api启动、停止spark streaming,宕机告警、自动重启等等功能支持,用户只需要关心业务代码,无需关注繁琐的...
HBase-SparkStreaming 从HBase表读取并写入HBase表的简单Spark Streaming项目 #Prereqs运行 创建一个要写入的hbase表:a)启动hbase shell $ hbase shell b)创建表create'/ user / chanumolu / sensor',{NAME =>'...
/todo:利用sparkStreaming对接kafka实现单词计数----采用receiver(高级API)//1、创建sparkConf.set(“spark.streaming.receiver.writeAheadLog.enable”,“true”) //开启wal预写日志,保存数据源的可靠性//2、创建...
Spark Streaming 读取 Kafka 数据源由两种模式,我会逐一讲解。构造函数为 使用了来接收数据,利用的是Kafka高层次的消费者api,对于所有的接收到的数据将会保存在中,然后通过启动来处理这些数据,默认会丢失,可...
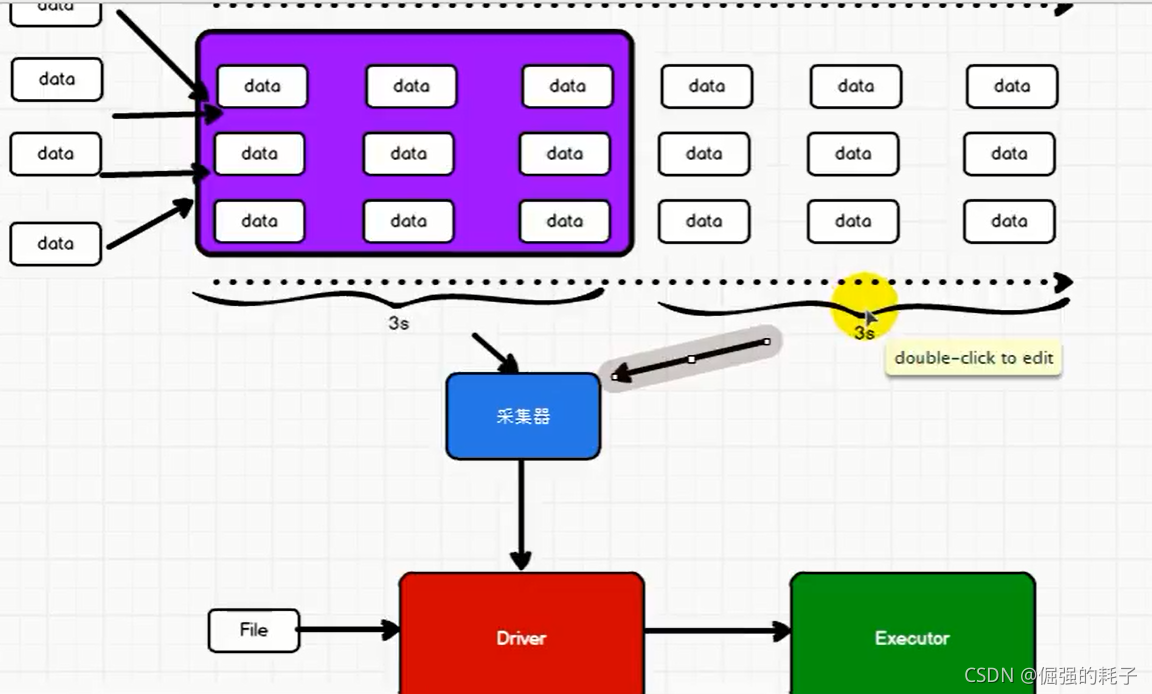
本文主要从以下几个方面介绍SparkStreaming: 一、SparkStreaming是什么 二、SparkStreaming支持的业务场景 三、SparkStreaming的相关概念 四、DStream介绍 五、SparkStreaming的机制 六、SparkStreaming的Demo...

生成的数据主要是模拟某学习网站学习视频课程的访问量(其中*以“ / class”开头的表示实战课程,然后通过流水线Flume + Kafka + SparkStreaming进行实时日志的收集,HBase来存储数据)*注意事项(使用的软件工具及...
总体来说,Structured Streaming 有更简洁的API、更完善的流功能、更适用于流处理。而spark streaming,更适用于与偏批处理的场景。
总体来说,Structured Streaming 有更简洁的API、更完善的流功能、更适用于流处理。而spark streaming,更适用于与偏批处理的场景。


支持动态调节 streaming 的 批次间隔时间 (不同于sparkstreaming 的 定长的批次间隔,StructuredStreaming中使用trigger实现了。) 支持在streaming过程中 重设 topics,用于生产中动态地增加删减数据源 添加了速率...
通过前几篇博客Spark Streaming 架构及工作原理DStream 编码实战,想必大家都已经有了一定的了解。这篇博客,我会和大家讲下如何基于进行开发与数据处理。首先我们来比较下,Structured Streaming 与 Spark ...
总体来说,Structured Streaming 有更简洁的API、更完善的流功能、更适用于流处理。而spark streaming,更适用于与偏批处理的场景。
目前实时平台主要基于JStorm与SparkStreaming构建而成,本次分享将着重于介绍携程如何基于SparkStreaming构建实时计算平台,文章将从以下几个方面分别阐述平台的构建与应用:携程实时平台在接入SparkStreaming之前,
从前一篇博客【Spark Streaming】(一)架构及工作原理,我们了解到是属于 Saprk API 的扩展,它支持实时数据流(live data streams)的可扩展,高吞吐(hight-throughput) 容错(fault-tolerant)的流处理。...
通过这种方式实现,刚开始的时候系统正常运行,没有发现问题,但是如果系统异常重新启动sparkstreaming程序后,发现程序会重复处理已经处理过的数据,这种基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中...
Spark-Streaming简单小项目 Spark Streaming实时解析flume和kafka传来的josn数据写入mysql 注意,以下文件不提供 配置c3p0-config.xml链接,链接数据库 配置log4j.properties、my.properties 另,还需将您的spark和...
1.理解Spark Streaming的工作流程。 2.理解Spark Streaming的工作原理。 3.学会使用Spark Streaming处理流式数据。 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 三、实验内容 (一)...
/2.接入kafka数据源(如何访问kafka集群?zookeeper)//访问组//访问主题//创建Dstream//3.处理数据//4.启动streaming程序r.print()//5.关闭资源。
套接字流是通过监听Socket端口接收的数据,相当于Socket之间的通信,任何用户在用Socket(套接字)通信之前,首先要先申请一个Socket号,Socket号相当于该用户的电话号码。然后编写代码,当有指定套接字连接产生时,...
DStream是Spark Streaming中的一个最基本的抽象,代表了一系列连续的数据流,本质上就是一系列的RDD。StreamingContext会根据设置的批处理的时间间隔将产生的RDD归为一批,这一批RDD就是一个DStream,该DStream里面...
(1)利用SparkStreaming从文件目录读入日志信息,日志内容包含: ”日志级别、函数名、日志内容“ 三个字段,字段之间以空格拆分。请看数据源的文件。 (2)对读入都日志信息流进行指定筛选出日志级别为error或warn...
java-sparkstreaming-kinesis 这个项目是用Java运行一个Spark Streaming应用程序 mvn clean compile assembly:assembly >> 使用 deps 构建 jar spark-submit --class ...
SparkStreaming是Spark核心API的扩展,用于可伸缩、高吞吐量、可容错地处理在线流数据。SparkStreaming可以从很多数据源获取数据,比如:Kafka、Flume、Twitter、ZeroMQ、Kinesis或TCP连接等,并可以用很多高层算子...
1.什么是SparkStreaming?2.SparkStreaming可以接受那些数据源?3.Dstream,我们可以进行哪两种操作?Sparkstreaming:构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地